챕터 5 - Convolutional Neural Networks
1. 왜 FC로는 안 되나
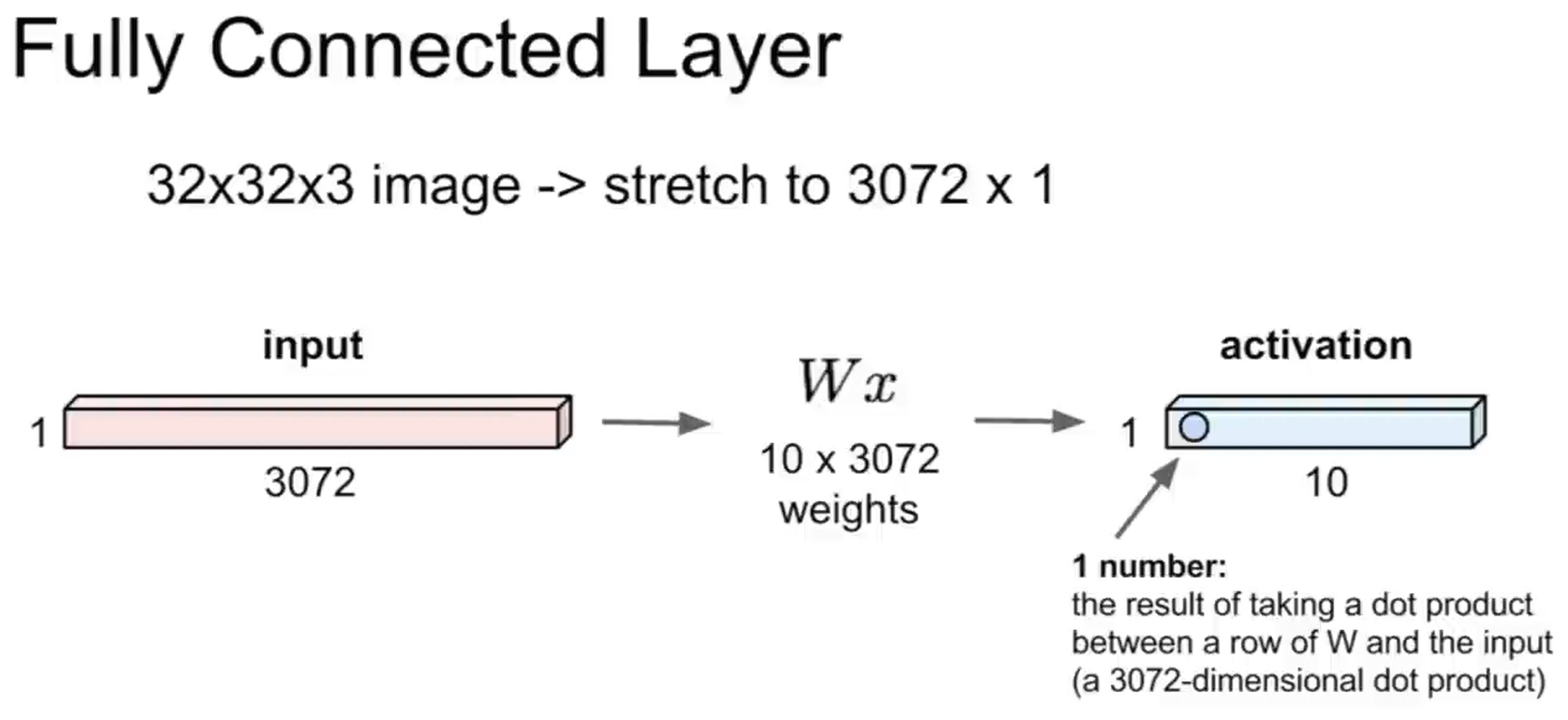
지금까지 다룬 Neural Network는 전부 FC(Fully-Connected) 레이어 기반이었다. 입력 이미지를 1D 벡터로 쭉 펼쳐서 가중치랑 곱하는 방식.

▲ FC 레이어 — 3072차원 벡터로 펼쳐서 Wx 연산 (출처: cs231n Lecture 5)
CIFAR-10 기준으로 32×32×3 이미지를 펼치면 3,072차원 벡터가 된다. 뉴런 하나당 3,072개 파라미터가 붙는다. 200×200×3짜리 이미지면? 뉴런 하나에만 120,000개다. 레이어가 쌓이면 감당이 안 된다.
근데 파라미터 수보다 진짜 문제가 따로 있다. 이미지를 1D로 펼치는 순간 공간 정보가 날아간다. 고양이 귀가 왼쪽 위에 있든 오른쪽 아래에 있든, 펼쳐버리면 그냥 숫자 배열일 뿐이다. 인접한 픽셀들 사이의 관계, 위치 정보 전부 사라진다.
CNN은 이미지를 3D 볼륨(Width × Height × Depth)으로 그대로 처리한다. 펼치지 않는 거다.
• • •
2. CNN의 역사
CNN이 2012년에 갑자기 툭 튀어나온 게 아니다. 수십 년 전 뇌과학 연구까지 거슬러 올라간다.
Hubel & Wiesel, 1959

▲ 고양이 시각 피질 실험 — Receptive Field 개념의 기원 (출처: cs231n Lecture 5)
고양이 뇌에 전극 꽂아서 시각 피질 뉴런이 어떻게 반응하는지 관찰한 실험이다. 밝혀진 게 두 가지였는데, 뉴런이 시야 전체를 보는 게 아니라 특정 로컬 영역에만 반응한다는 거랑, 빛의 방향에 따라 반응하는 뉴런이 따로 있다는 거다. 가로선에 반응하는 뉴런, 세로선에 반응하는 뉴런 이런 식으로. 이게 Receptive Field 개념의 기원이다.
계층적 구조 — Simple / Complex / Hypercomplex cells

▲ 시각 피질의 계층적 구조 — Simple → Complex → Hypercomplex (출처: cs231n Lecture 5)
더 파고들면 뇌 시각 처리가 계층 구조로 되어 있다는 걸 알 수 있다. Simple cell은 빛의 방향에만 반응하고, Complex cell은 방향이랑 움직임 둘 다 보고, Hypercomplex cell은 선의 끝점같은 더 복잡한 것에 반응한다. 낮은 레이어에서 단순한 feature, 높은 레이어로 갈수록 복잡한 feature를 학습하는 CNN이랑 구조가 그대로 맞아떨어진다. 우연이 아니다.
Neurocognitron, 1980 (Fukushima)

▲ Neurocognitron — SCSCSC... 샌드위치 구조, Conv+Pooling의 원형 (출처: cs231n Lecture 5)
Hubel & Wiesel 실험 결과를 컴퓨터로 구현해보려는 첫 시도다. Simple cell 역할을 하는 층(학습 가능한 파라미터)이랑 Complex cell 역할을 하는 층(pooling)을 번갈아 쌓는 SCSCSC... 구조를 제안했다. 지금 봐도 Conv + Pooling이랑 거의 같다.
LeNet, 1998 (LeCun et al.)

▲ LeNet-5 — Conv → Subsampling 반복 후 FC, 실제 수표 인식에 배포 (출처: cs231n Lecture 5)
실제로 동작하는 최초의 CNN이다. 손글씨 숫자 인식에 써서 당시 은행 수표 처리에 실제로 배포됐다. backprop으로 필터를 학습시키는 방식을 제대로 정립했고, Conv → Subsampling 반복하다가 FC로 마무리하는 구조가 지금이랑 거의 똑같다.
AlexNet, 2012
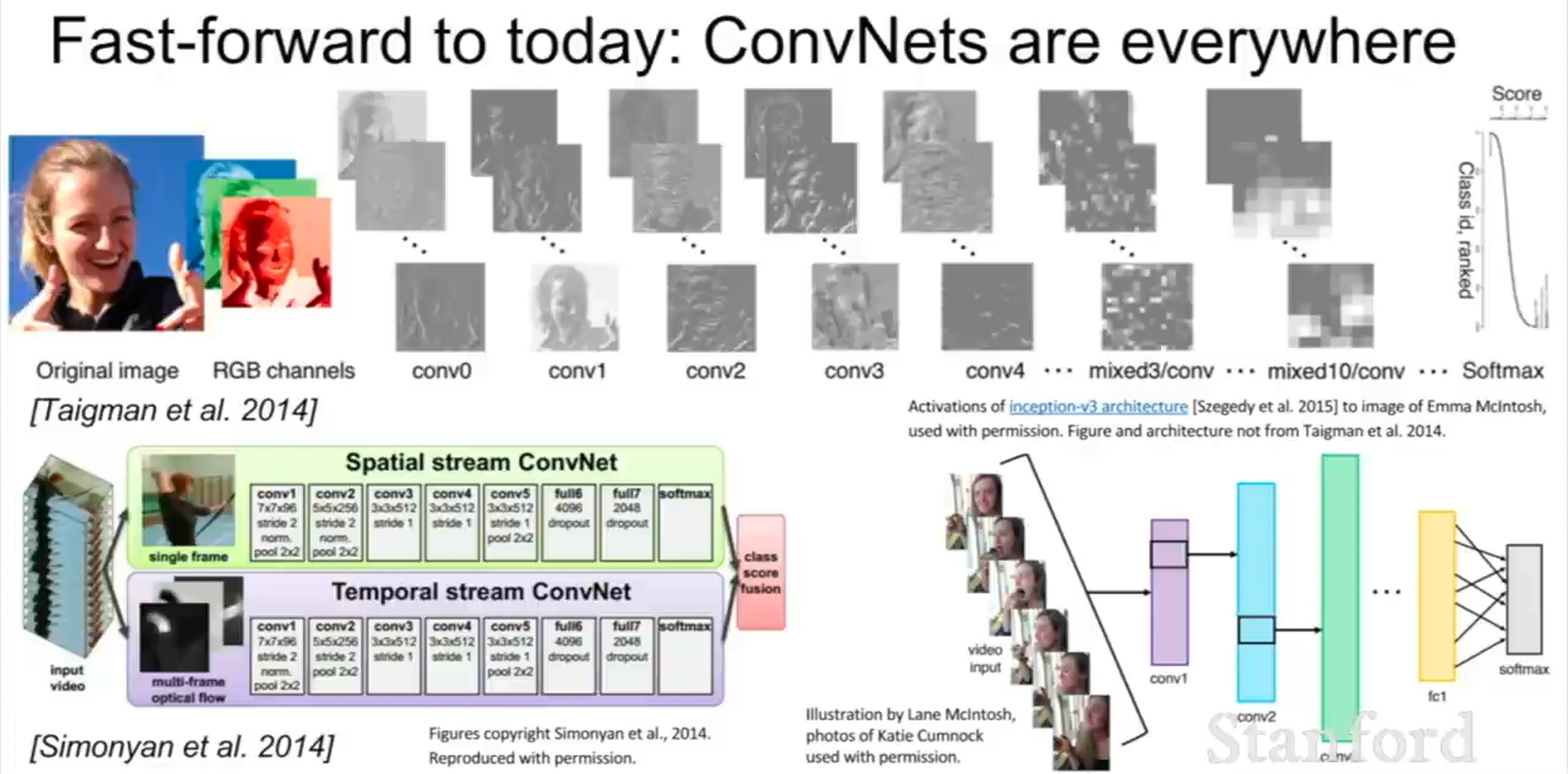
▲ AlexNet 구조 + 첫 번째 Conv 레이어 필터 시각화 (edge, color blob) (출처: cs231n Lecture 5)
2012년 ImageNet 대회에서 기존 2등이랑 error rate 차이가 10%p 넘게 났다. 그냥 조금 이긴 게 아니라 완전히 발라버린 거다. GPU 병렬 학습, ReLU, Dropout 조합이 먹혔고, 이때부터 딥러닝이 컴퓨터 비전 판을 먹기 시작했다. 오른쪽 그림이 첫 번째 Conv 레이어 필터들인데, edge랑 color blob 형태가 나온다. 학습이 제대로 됐다는 거다. VGG, GoogLeNet, ResNet 같은 구조들은 Lecture 9에서 따로 다룬다.
• • •
3. Convolutional Layer
FC 레이어는 이미지를 1D로 펼쳤지만 Conv 레이어는 3D 그대로 처리한다.

▲ Conv 레이어 — 32×32×3 이미지를 3D 볼륨으로 그대로 처리 (출처: cs231n Lecture 5)
핵심은 필터(filter)다. 필터는 작은 가중치 행렬인데, 공간 크기는 작아도 depth는 항상 입력 depth와 같다. 32×32×3 이미지에 5×5 필터를 쓰면 필터 크기는 5×5×3이 된다. 이 필터를 이미지 위에서 슬라이딩하면서 겹치는 부분과 dot product를 계산한다.
▲ 5×5×3 필터 — depth는 항상 입력 depth와 동일 (출처: cs231n Lecture 5)
이걸 이미지 전체에 걸쳐 반복하면 숫자들이 쌓여서 2D 행렬 하나가 만들어진다. 이게 Activation Map이다. 필터 하나당 Activation Map 하나.

▲ 필터 1개 → Activation Map 1개 (28×28×1) (출처: cs231n Lecture 5)
필터를 6개 쓰면 Activation Map이 6개 나오고, 이걸 depth 방향으로 쌓으면 28×28×6짜리 출력 볼륨이 된다.
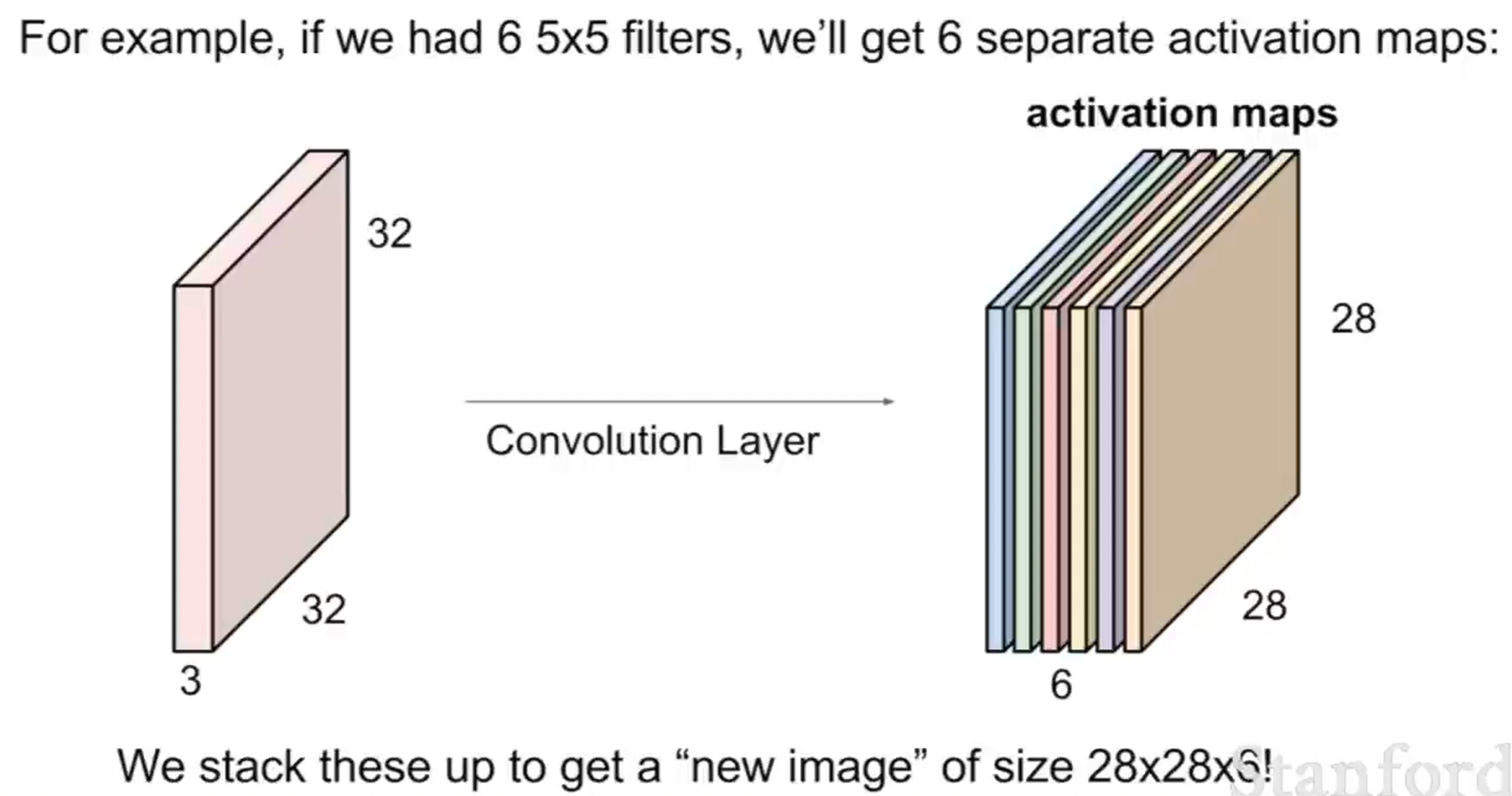
▲ 6개 필터 → 28×28×6 출력 볼륨 (출처: cs231n Lecture 5)
아래는 VGG-16을 학습시키고 나서 각 레이어 필터들을 시각화한 거다.

▲ VGG-16 레이어별 필터 시각화 — 낮은 레이어는 edge, 깊어질수록 추상적 (출처: cs231n Lecture 5)
첫 레이어(Conv1_1)는 edge, color 같은 단순한 패턴이고, 중간(Conv3_2)으로 가면 좀 더 복잡한 텍스처 형태가 된다. 깊어질수록 점점 추상화된다는 게 실제로 눈으로 보인다.
아래가 실제 이미지에 대한 activation map과 합성곱 수식이다.

▲ 실제 이미지의 activation map — 필터마다 다른 부위에 반응 (출처: cs231n Lecture 5)
• • •
4. Output Size 계산
Conv 레이어 출력 크기는 세 개 하이퍼파라미터로 결정된다: Filter size(F), Stride(S), Padding(P).
Stride
필터를 몇 칸씩 이동할지다. stride=1이면 한 칸, stride=2면 두 칸씩 건너뛴다. 당연히 stride가 클수록 출력이 작아진다.

▲ stride=1 → 5×5 output (출처: cs231n Lecture 5)

▲ stride=2 → 3×3 output (출처: cs231n Lecture 5)
stride=3은 어떨까? 7×7 입력에 3×3 필터, stride=3이면 (7-3)/3+1 = 2.33...이다. 정수가 아니라 에러난다. 필터가 이미지 끝에서 딱 안 맞아떨어지는 상황이다.

▲ stride=3 → doesn't fit! 정수가 안 나오면 에러 (출처: cs231n Lecture 5)
Output Size 공식

▲ Output size 공식 + stride별 계산 예시 (출처: cs231n Lecture 5)
padding 없을 때는 (W - F) / S + 1이다. 이 값이 정수로 떨어져야 유효한 조합이다. padding 포함하면:
Zero Padding

▲ Zero Padding — 0으로 채운 후 3×3 filter, stride=1 적용 → 7×7 output 유지 (출처: cs231n Lecture 5)

▲ F=3 → P=1, F=5 → P=2, F=7 → P=3 — P=(F-1)/2로 공간 크기 유지 (출처: cs231n Lecture 5)
padding 없이 Conv를 계속 적용하면 크기가 32 → 28 → 24 → 20... 이런 식으로 빠르게 줄어든다. 깊은 네트워크를 쌓다 보면 금방 사라진다. 그래서 입력 주변에 0을 채워서 크기를 유지하는 게 Zero Padding이다. F=3이면 P=1, F=5이면 P=2, 즉 P = (F-1)/2로 설정하면 입출력 크기가 같아진다.
Zero Padding 말고도 방식이 있긴 하다.

▲ Padding 종류 비교 — Zero / Reflection / Replicate (직접 제작)
Reflection Padding은 가장자리를 거울처럼 반사해서 채우는 방식이고, Replicate Padding은 끝 픽셀을 그대로 복사한다. GAN이나 style transfer 같은 생성 모델에서는 Zero Padding 쓰면 테두리에 아티팩트가 생기는 경우가 있어서 Reflection을 더 선호하기도 한다. 일반 분류 모델에서는 Zero Padding이 기본값이다.
계산 예시

▲ 입력 32×32×3, 10개 5×5 필터, stride=1, pad=2 → 출력 크기 계산 (출처: cs231n Lecture 5)

▲ 파라미터 수 계산 — (5×5×3+1)×10 = 760개 (출처: cs231n Lecture 5)
입력 32×32×3, 필터 10개 (5×5), stride=1, pad=2라면 출력 크기는 32×32×10이다. 파라미터 수는 (5×5×3 + 1) × 10 = 760개. 만약 FC 레이어였다면 같은 입출력에 9,830,400개가 필요하다. 760 대 9,830,400이다.
Conv Layer Summary

▲ Conv Layer 하이퍼파라미터 정리 + 자주 쓰는 setting (출처: cs231n Lecture 5)
하이퍼파라미터 K(필터 수), F(필터 크기), S(stride), P(padding) 네 개로 Conv 레이어가 결정된다. K는 보통 2의 제곱수(32, 64, 128, 512...)를 쓰고, F=3, S=1, P=1 조합이 제일 많이 쓰인다.
1×1 Convolution

▲ 1×1 Conv — 공간 유지하면서 depth만 압축 (56×56×64 → 56×56×32) (출처: cs231n Lecture 5)
처음 보면 1×1이 무슨 의미인가 싶다. 근데 depth 방향으로는 전체를 본다. 56×56×64 입력에 1×1 필터 32개를 쓰면 56×56×32가 된다. 공간 크기는 그대로고 채널만 절반으로 줄었다.
중요한 건 이게 그냥 채널 수를 줄이는 게 아니라 학습으로 줄인다는 거다. 어떤 채널 조합이 중요한지를 backprop이 알아서 찾는다. GoogLeNet Inception 모듈이나 ResNet bottleneck에서 3×3 Conv 전에 1×1을 먼저 붙여서 채널을 줄인 다음 연산하는 방식으로 파라미터를 대폭 아낀다.
• • •
5. Parameter Sharing과 Local Connectivity
Local Connectivity

▲ 각 뉴런은 입력 전체가 아닌 로컬 영역(Receptive Field)만 연결 (출처: cs231n Lecture 5)
각 뉴런이 입력 전체가 아니라 로컬 영역만 본다. 이 연결 범위가 Receptive Field다. 5×5 필터면 한 뉴런이 보는 영역이 5×5×3 = 75개 값이다. FC였으면 3,072개 전부 봤을 텐데.
Parameter Sharing

▲ Activation Map의 28×28 뉴런이 모두 같은 필터 가중치 공유 (출처: cs231n Lecture 5)
Activation Map의 28×28 뉴런이 전부 같은 필터 가중치를 쓴다. 이미지 왼쪽 위에서 가로선 찾는 필터가 오른쪽 아래에서도 같은 가중치로 가로선을 찾는 거다. 어디서든 비슷한 패턴이 나오는 이미지 특성상 이게 말이 된다. 이런 성질을 Translation Equivariance라고 한다.

▲ 5개 필터 → 28×28×5 볼륨. 같은 위치의 뉴런 5개는 같은 공간을 보지만 서로 다른 것을 찾는다 (출처: cs231n Lecture 5)
3×3 두 번 = 5×5 한 번? Receptive Field 누적

▲ 3×3 Conv 두 번 → 5×5 receptive field. 파라미터 25개 vs 18개 (직접 제작)
3×3 Conv를 두 번 쌓으면 마지막 값 하나가 입력의 5×5 영역을 반영한다. 5×5 필터 한 번 쓰는 거랑 수용 범위가 같은데, 파라미터는 25개 vs 18개로 적고, ReLU를 한 번 더 넣을 수 있으니까 비선형성도 더 많다. VGG가 3×3 필터만 쭉 쓰는 이유가 이거다.
• • •
6. Pooling Layer

▲ Pooling — 공간 크기만 줄이고 depth는 유지 (224×224×64 → 112×112×64) (출처: cs231n Lecture 5)
Pooling 레이어는 공간 크기를 줄이는 역할이다. 파라미터가 없고, depth는 손대지 않는다. 224×224×64가 112×112×64가 되는 것처럼 공간만 줄고 채널은 그대로다. 각 채널에 독립적으로 적용된다.
Max Pooling

▲ Max Pooling 2×2, stride=2 — 4개 값 중 최대값만 남김 (출처: cs231n Lecture 5)
2×2 영역에서 최대값 하나만 남기는 거다. stride=2로 하면 공간 크기가 딱 절반이 된다. "이 4개 중에 이 feature가 있긴 한가?"에 대한 답이라고 보면 된다. 있으면 그냥 강도 그대로 남기고, 없으면 0이 된다. Average Pooling보다 Max가 더 잘 되는 건 실험적으로 증명됐고, 이 직관이랑도 맞아떨어진다.
Pooling의 부수 효과로 Spatial Invariance가 생긴다. 고양이 귀가 한 픽셀 옆으로 이동해도 같은 2×2 영역 안이면 Max Pooling 결과가 달라지지 않는다. 위치 변화에 어느 정도 강건해진다는 거다.
• • •
7. ConvNet 전체 구조

▲ [CONV → ReLU] 반복 후 POOL — 이걸 쌓다가 FC로 마무리 (출처: cs231n Lecture 5)
[CONV → ReLU]를 N번 반복하다가 POOL로 다운샘플링, 이걸 다시 반복하다가 마지막에 FC로 class score를 뽑는다. 전체가 미분 가능하니까 backprop이 그대로 통한다.

▲ 자동차 이미지 — CONV→RELU→POOL이 반복되며 feature가 추출되는 과정 (출처: cs231n Lecture 5)

▲ 전체 ConvNet 구조 — CONV, RELU, POOL 거쳐 FC에서 class score 출력 (출처: cs231n Lecture 5)
| 레이어 | 하는 일 | 파라미터 |
|---|---|---|
| CONV | 로컬 패턴 추출 (edge, texture, ...) | 있음 |
| ReLU | 비선형성 | 없음 |
| POOL | 공간 크기 줄이기 | 없음 |
| FC | 최종 분류 | 있음 |
레이어가 쌓일수록 앞 레이어 Receptive Field가 누적되면서 더 넓은 영역을 반영한다. 낮은 레이어에서 edge 같은 low-level feature를 잡고, 높은 레이어로 갈수록 "귀", "눈", "코" 같은 high-level feature로 추상화된다. FC 레이어가 이걸 최종적으로 조합해서 "이게 고양이다"라고 판단하는 구조다.
핵심 요약
| 개념 | 한 줄 요약 |
|---|---|
| FC vs CNN | FC는 공간 정보 소실 + 파라미터 폭발 → CNN은 3D 볼륨 그대로 처리 |
| Convolutional Layer | 필터 슬라이딩 → dot product → Activation Map |
| Output Size 공식 | \(\frac{W - F + 2P}{S} + 1\) |
| Zero Padding | P = (F-1)/2 → 입출력 크기 동일 유지 |
| Parameter Sharing | 같은 필터를 전체 위치에서 재사용 → 파라미터 수 급감 |
| Local Connectivity | 각 뉴런은 Receptive Field만 연결 |
| Receptive Field 누적 | 3×3 두 번 = 5×5 한 번, 파라미터 25→18 |
| 1×1 Convolution | 공간 유지, depth 압축 (학습된 조합), Bottleneck에 활용 |
| Max Pooling | 공간 다운샘플링, depth 유지, Spatial Invariance |
| ConvNet 구조 | [CONV → ReLU] × N → POOL → 반복 → FC → Softmax |
참고
• • •
다음: Lecture 6 - Training Neural Networks I